선데이토즈의 ML 프로젝트
선데이토즈에서는 게임 개발과 더불어 다양한 ML 프로젝트도 진행하고 있습니다.
오늘은 ML이 어떻게 활용되고 있는지 그리고 그 기반이 되는 기술들에 대하여 소개하고자 합니다.
1. 유저 이탈 예측
게임 운영이나 마케팅시 중요한 지표 중 하나가 바로 리텐션(Retention) 입니다. 리텐션은 한번 게임을 시작한 유저들이 얼마나 지속적으로 게임을 즐기고 있는지를 나타내는 지표입니다. 잔존율이라고도 부르는 이 데이터는 게임이 신규 게임인지, 오래된 게임인지에 관계없이 중요한데요. 오래된 게임일수록 새로 가입하는 유저가 적기 때문에 기존 플레이하고 있는 유저의 잔존을 높이는 것이 중요할 수 밖에 없습니다.
유저의 잔존을 높이기 위해 선데이토즈에서는 ML 을 활용하여 과거 데이터를 보고 이탈할 가능성이 높은 유저를 찾아 대응하는 시스템을 갖추고 있습니다. 이 시스템을 적용하기 위해서 ‘이탈’이 무엇인지, 그리고 이탈을 유발하는 요인에 대해 먼저 정의해야 했습니다. 단순히 유저의 접속 여부를 이탈을 판단하는 기준으로 정한다면 게임을 재미있게 즐기고 있지만 바쁜 일이 생겨 잠시 게임에 접속을 못한 유저들을 모두 이탈한 유저로 간주하게 될 것입니다. 이 경우 실제 이탈 유저가 아니라 단기 미접속 유저에 대한 정보들까지 무절제하게 수집됨으로써 올바르게 학습을 진행할 수가 없게 됩니다. 따라서 이탈 유저와 미접속 유저를 구분할 수 있는 기준이 필요한데요. 이 시스템에서는 1주일 이상 접속 하지 않는 유저를 이탈 유저로 간주하도록 기준을 정의했습니다. 이 기준은 게임의 장르나 특성에 따라 선택해야 하는 값입니다.
이처럼 기준을 정한 후에는 게임 내에서 쌓고 있던 데이터들을 통계적으로 전처리하는 과정을 거칩니다. 이 부분이 가장 어려운 부분 중 하나라고 생각하는데요. 현재 어떤 데이터를 뽑을 수 있는지, 그리고 어떤 데이터가 우리가 예측하고자 하는 이탈과 관련이 있는지, 데이터의 특성은 어떤지, 데이터에 문제는 없는지 등등 고려할 점이 매우 많습니다. 시스템을 적용하면서 여러 데이터들을 다양한 방식으로 통계내어 테스트 해보았고 또 데이터 특성상 이탈 유저의 데이터가 이탈하지 않는 유저들의 데이터에 비해 매우 적어 발생하는 클래스 불균형 문제도 해결해야 했습니다.
이러한 일련의 데이터 추출, 전처리 과정은 Google Cloud Platform(GCP) 상의 BigQuery, Cloud Functions 등의 서비스를 사용하여 이루어 졌습니다. 이미 많은 유저들이 플레이하고 있는 게임들이기 때문에 로그가 실시간으로 많이 쌓이고 있었지만 BigQuery 의 빠른 처리 속도 덕분에 빠르게 테스트하며 구현할 수 있었습니다.
이렇게 학습 데이터를 생성하고 나면 모델 학습을 진행해야 하는데 이 시스템에서는 직접 모델을 생성하는 것이 아닌 GCP 서비스 중 하나인 AutoML Tables 를 사용하여 모델을 구축하고 학습하였습니다.
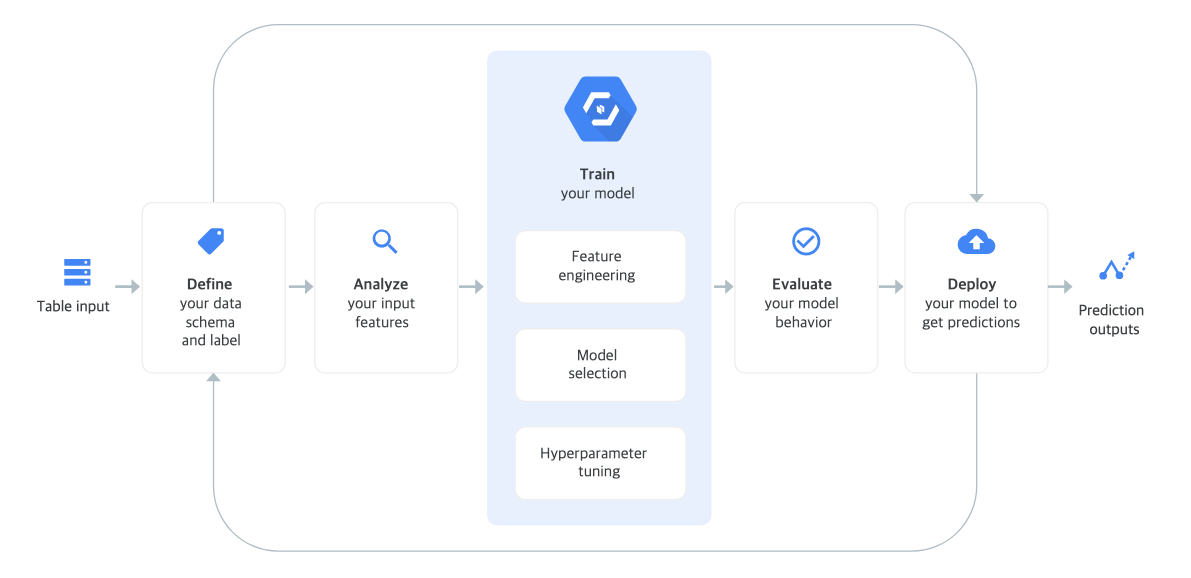
위 이미지가 AutoML Tables 의 작동 방식을 설명한 것입니다. 인풋으로 테이블형 데이터를 넣어주고 타겟 열, 학습 시간, 최적화 목표 등을 설정하면 자동으로 모델 학습을 하는 구조입니다. 학습된 결과 모델은 배치 예측을 진행할 수도 있고 서버에 배포하여 실시간 예측도 할 수 있습니다.
AutoML Tables 로 유저 이탈 학습을 해보니 정확도, 정밀도, 재현율 모두 만족할만한 결과가 나왔습니다. 현재 실 서비스에서 이 결과 모델을 적용하여 이탈할 확률이 높은 유저들을 선별하여 보상을 지급하였고 이후 분석 결과 유저 잔존 에 유의미한 효과를 거두고 있습니다.
이 글을 읽으시는 분들도 테이블형 데이터로 모델을 생성하고 싶다면 AutoML Tables 를 고려해보시길 추천드립니다. 최근에는 BigQuery 에서 SQL 문으로 AutoML 모델을 생성하는 기능이 추가되어 더욱더 쉽고 빠르게 적용할 수 있습니다.
2. 게임 AI
애니팡 시리즈와 같은 매치 3 게임의 경우 스테이지가 계속 업데이트 되면서 맵 제작, 밸런싱 등을 하는데 많은 시간이 소요됩니다. 만약 게임을 사람처럼 플레이할 수 있는 AI 를 제작한다면 그러한 부분에서 큰 도움을 줄 수 있습니다. 따라서 게임 AI 를 만드는 일도 꾸준히 진행하고 있습니다.
게임 장르가 다양한만큼 각 게임 특성에 맞는 학습 방식과 알고리즘을 사용해야 합니다. 규칙 기반(Rule-based) AI 를 만들수도 있고 지도학습, 강화학습 등의 학습방식을 사용할 수도 있습니다. 예를 들어보자면 캔디 크러쉬로 유명한 King 사에서는 지도학습을 이용하여 Human-like Playtesting을 하는 사례가 있습니다. 또 강화학습을 이용하여 매치 3 게임 AI를 만드려고 한 시도도 있었습니다. 유명한 알파고의 경우에는 지도학습과 강화학습을 모두 사용해서 제작이 되었고 계속 발전하면서 결국 인간 기보 데이터 없이 강화학습만으로도 AI 를 만들어 냈습니다.
선데이토즈에서도 지도학습, 강화학습 등을 사용한 사례가 있습니다만 이번에는 강화학습에 대해서만 살펴 보겠습니다.
강화학습은 금용, 신약개발, 로보틱스 등 다양한 분야에서 사용됩니다. 게임에서도 많이 사용이 되는데 게임의 경우 마르코프 결정 과정으로 표현하기 쉽기 때문이지 않을까 싶습니다. 마르코프 결정 과정(MDP, Markov Decision Process)이란 의사결정 과정을 모델링하는 틀을 제공하며 강화 학습 문제를 정의할 때 사용됩니다.
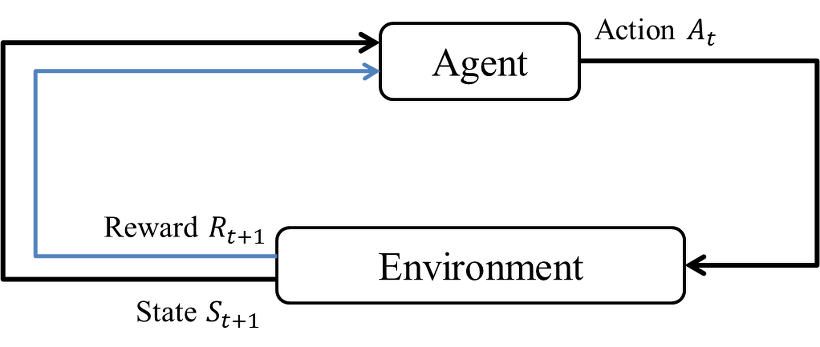
위 그림이 MDP 의 동작을 표현한 것입니다. MDP 의 구성 요소로는 상태(state), 행동(action), 전이 확률(transition probability), 보상(reward), 할인인자(discount factor) 등이 있습니다. 각 요소에 대한 설명과 MDP 에 대한 더 자세한 설명은 여기를 참고하시고 이번에는 매치 3 게임에서의 예시만 확인해보겠습니다.

위 이미지는 애니팡4의 한 스테이지를 캡쳐한 것입니다. 이것을 MDP로 표현하다면 먼저 상태는 9 x 9 퍼즐판의 블럭들, 특수블럭들, 오브젝트들과 남은 턴수, 남은 미션수를 인코딩하여 표현할 수 있습니다. 행동은 특정 블럭 스와이프 또는 아이템 사용이 될 수 있습니다. 보상은 다양한 방법으로 설계할 수 있습니다. 첫번째 가장 간단한 방법으로는 스테이지를 클리어하면 1, 실패하면 -1, 스테이지를 진행중일때는 0의 보상을 주는 방법이 있습니다. 이렇게 하면 보상이 스테이지가 끝날때만 발생하는데 이를 sparse reward 라고 합니다. 또 다른 방식으로는 해당 스테이지의 주어진 미션이 차감될때 보상을 주거나 스테이지 점수와 미션 등을 조합해서 보상을 설계할수도 있습니다.
이제 실제 작업시 테스트 해봤던 강화학습 알고리즘 2가지만 소개해 보겠습니다.
2.1. NFSP(Neural Fictitious Self-Play)
NFSP 는 2016년 발표된 논문에서 나온 알고리즘입니다. Fictitious Play 의 개념은 1951년 George W. Brown 에 의해서 소개되었는데 이는 2인 게임에서 내쉬균형을 찾는 학습 규칙입니다. Fictitious Play 는 시간 데이터를 다루지 못하는 등의 한계점이 있어 이를 보완한 Fictitious Self-Play 가 나왔고 이에 신경망을 추가한 것이 NFSP 입니다.
NFSP 는 average-policy network 와 action-value network 두 가지로 구성되며 각각 학습을 위한 메모리들로 구성됩니다. 저자인 Heinrich & Silver 는 NFSP 가 처음으로 내쉬균형을 근사한 문제에 대한 사전 도메인 지식이 없어도 되는 end-to-end 강화학습 방식이라고 소개합니다.

위 이미지가 NFSP 의 알고리즘을 기술한 것입니다. 자세한 내용은 공개되어 있는 논문을 통해 확인하실 수 있습니다.
2.2. PPO(Proximal Policy Optimization)
PPO 는 OpenAI 에서 발표한 알고리즘으로 범용적으로 적용할 수 있는 강화학습 알고리즘입니다. TRPO(Trust Region Policy Optimization) 알고리즘에서 기원했는데 TRPO 의 장점은 그대로 가져가면서 TRPO 보다 더 간단하게 구현할 수 있습니다.
Unity MLAgents 에서 Soft Actor-Critic 과 함께 기본적으로 제공하는 강화학습 알고리즘 중에 하나이기도 합니다.
PPO 는 policy gradient 방식으로 policy 란 주어진 상태에서 어떤 행동을 해야하는가에 대한 정책을 의미합니다. Policy gradient 는 policy 를 직접적으로 모델링하는 방식입니다. Policy gradient 방식은 보상 value 를 기반으로 하는 방식보다 수렴이 잘되며 행동 자체가 연속적인 경우 효과적입니다. 하지만 전역적인 최적해를 보장하지는 않는 단점이 있습니다.
PPO 의 알고리즘은 아래와 같으며 자세한 내용은 논문에서 확인할 수 있습니다.

3. 지표 예측
모바일 게임은 DAU(Daily Active User), 매출 관련 지표, 유저 활동성 관련 지표 등등 여러 지표를 기반으로 운영됩니다.
선데이토즈에서도 내부적으로 여러 지표를 실시간으로 확인할 수 있는 툴이 존재합니다. 현재는 실시간 데이터와 과거 데이터만을 제공하지만 이제 몇 일뒤 미래에는 지표가 어떨지 예측하여 제공하기 위한 작업을 진행하고 있습니다.
예측을 제공하려는 지표 중 상당수가 특정 시간 혹은 특정 날짜와 그에 대응하는 데이터가 있는 시계열 데이터(Time series data) 입니다. 따라서 이러한 시계열 데이터 예측을 위하여 RNN(Recurrent Neural Network) 의 일종인 LSTM, 확률 통계적 모형, 단순 회귀모형 등 다양한 모델을 테스트 하고 있습니다.
4. 마치며
지금까지 선데이토즈에서 진행하고 있는 ML 프로젝트 3가지를 소개드렸습니다.
이번에 소개드린 내용 이외에도 NLP, Recommendation 등 다양한 분야에서 다양한 기술을 활용한 프로젝트를 진행할 계획도 있습니다.
다음에 또 기회가 된다면 새로운 내용으로 찾아 뵙겠습니다. 감사합니다.